01 Overview
Large language models have strong factual recall but often fail on curriculum cognition: which concepts come first, which skills a problem tests, and where a topic sits in the textbook hierarchy. K12-KGraph is a three-part resource that grounds evaluation and training in structured textbook knowledge.
-
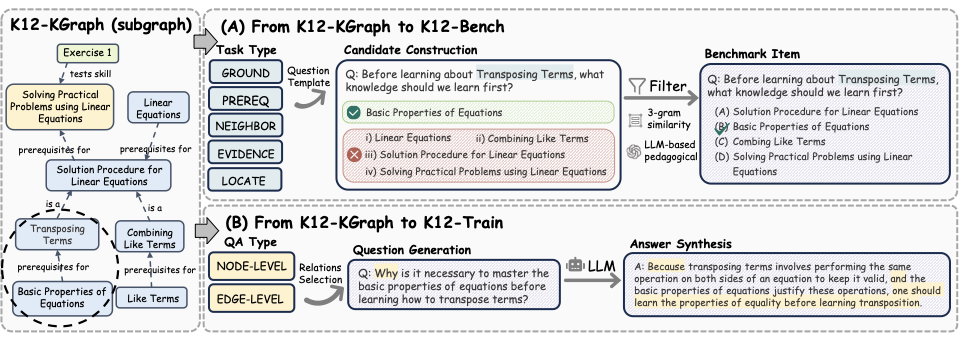
K12-KGraph. 10,685 nodes and 23,278 edges extracted from official PEP textbooks with OCR, schema-constrained LLM extraction, and human verification.
-
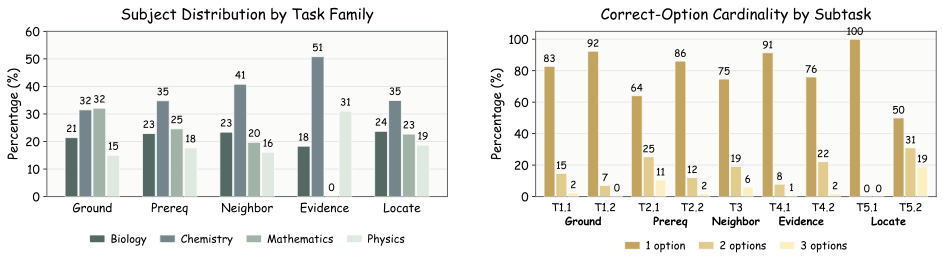
K12-Bench. 23,640 multi-select questions across five curriculum tasks: Ground, Prereq, Neighbor, Evidence, and Locate.
-
K12-Train. 2,267 KG-guided SFT pairs that outperform same-sized subsets of 8 mainstream SFT corpora on GaokaoBench and EduEval.
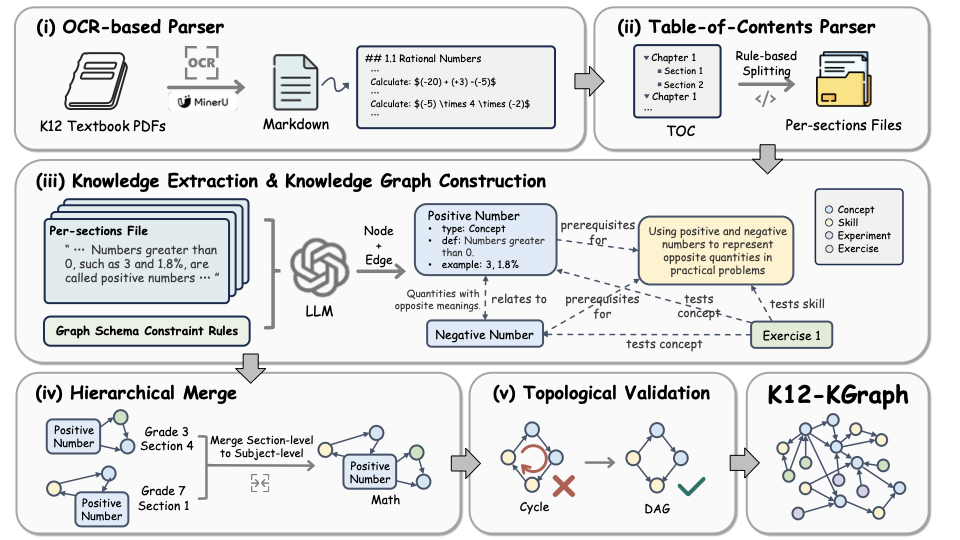
Schema of K12-KGraph: 7 node types & 9 relations grounded in textbook structure.